Also available for Chinese Finnish French German Swedish
Digital grammars are grammars usable by computers, so that they can mechanically perform tasks like interpreting, producing, and translating languages. The GF Resource Grammar Library (RGL) is a set of digital grammars which, at the time of writing, covers 28 languages. These grammars are written in GF, Grammatical Framework, which is a programming language designed for writing digital grammars.
The grammars in the RGL have been written by linguists, computer scientists, and programmers who know the languages thoroughly, both in practice and in theory. Almost 50 persons from around the world have contributed to this work, and ongoing projects are expected to give us many new languages soon.
The leading idea of the RGL is that different languages share large parts of their grammars, despite their observed differences. One important thing that is shared are the categories, that is, the types of words and expressions. For instance, every language in RGL has a category of nouns, but what exactly a noun is varies from language to language. Thus English nouns have four forms (singular and plural, nominative and genitive, as in house, houses, house's, houses') whereas French nouns have just two forms (singular and plural maison, maisons, "house"), but they also have a piece of information that English nouns don't have, namely gender (masculine and feminine). Chinese nouns have just one form (房子 fangzi "house"), which is used for both singular and plural, but in addition, a little bit like the French gender, they have a classifier (间 jian for the word "house"). German nouns have 8 forms and a gender, Finnish nouns have 26 forms, and so on.
This document provides a tour of the digital grammars in the RGL. It is intended to serve at least three kinds of readers. In the decreasing order of the number of potential readers,
The document has two main parts: Words and Syntax. Both parts have a general section, explaining the RGL structure from a multilingual perspective, followed by a specific section, going into the details of the grammar in a particular language. The general sections are the same in all languages. The specific sections differ in length and detail, depending on the complexity of the language and on what aspects are particularly interesting or problematic for the language in question.
Categories of words are called lexical categories. The language-specific variation in lexical categories is due to morphology, that is, the different forms that one and the same word can have in different contexts. If we look at the 28 languages in the RGL, we can see that the classification of words is common to all the languages, and the differences are in morphology. In this chapter, we will explain all lexical categories and give an overview of their morphological aspects. Details of morphology for each language is given in the language-specific documents.
The most important categories of words are given in the following table. More precisely, we will give the categories of content words, which, so so say, describe things and events in the real world. Content words are distinguished from structural words, whose purpose is to combine words into syntactic structures. Each category of content words may have thousands of words, and new words can be introduced continuously; therefore, these categories are also called open categories. In contrast, structural words are very few (maybe some dozens), and new ones are very seldom added.
Each category has a GF name, that is, a short symbolic name, which is the name actually used in the GF program code. In the text we usually use the text names, but will sometimes find the GF names handy to use as well, since they give us a short and precise way to state grammatical rules.
| GF name | text name | example | inflectional features | inherent features | semantics | |
|---|---|---|---|---|---|---|
N |
noun | house | number, case | gender, classifier | n = e -> t |
|
PN |
proper name | Paris | case | gender | e |
|
A |
adjective | blue | gender, number, case, degree | position | a = e -> t |
|
V |
verb | sleep | number, person, tense, aspect, mood | subject case | v = e -> t |
|
Adv |
adverb | here | (none) | adverb type (place, time, manner) | adv = v -> v |
|
AdA |
adadjective | very | (none) | (none) | a -> a |
|
In addition to the names and examples, the table lists the inflectional features and inherent features typical of each category. Inflectional features are those that create different forms of words. For instance, French nouns have forms for number (singular and plural) - or, as one often says, French nouns are inflected for number. In contrast to number, the gender does not give rise to different forms of French nouns: maison ("house") is feminine, inherently, and there is no masculine form of maison. (Of course, there are some nouns that do have masculine and feminine forms, such as étudiant, étudiante "male/female student", but this only applies to a minority of French nouns and shouldn't be taken as an indication of an inflectional gender.)
The features given in the table are rough indications for what one can expect in different languages. Thus, for instance, some languages have no gender at all, and hence their nouns and adjectives won't have genders either. But the table is a rather good generalization from the 28 language of the RGL: we can safely say that, if a language does have gender, then nouns have an inherent gender and adjectives have a variable gender. This is not a coincidence but has to do with syntax, that is, the combination of words into complex expressions. Thus, for instance, nouns are combined with adjectives that modify them, so that
bleu + livre = livre bleu ("blue book", masculine)
We will return to syntax later. At this point, it is sufficient to say that the morphological features of words are not there just for nothing, but they play an important role in how words are combined in syntax. In particular, they determine to a great extent how agreement works, that is, how the features of words depend on each other in combinations.
Notice: this section, and all "semantics" columns can be safely skipped, because the semantics types do not belong to the RGL proper, and don't appear anywhere in the code. Their understanding can however be useful, in particular for programmers who want to use the RGL to express logical relations, ontologies, etc
The last column in the category table shows the semantic type corresponding to each category. This type gives an indication
of the kind of meaning that the word of each type has. Starting from the simplest meanings, e is the type of entities that serve as meanings of proper names. Nouns, adjectives, and verbs have the type e -> t, which means
functions from entities to propositions (where the symbol t for propositions comes from truth values). Such a function can be applied to an entity to yield a proposition.
The type t itself is reserved for sentences, which are formed in syntax by putting words together.
For example, the sentence Paris is large
involves an application of the adjective large to Paris, and yields the value true if large applies to Paris.
Paris is a capital works in the similar way with the noun capital, and Paris grows with the verb grow.
The semantic types will be useful in syntax to explain the ways in which expressions are combined. They are also useful in
explaining some differences between categories. For example, the categories PN and N are different, because a PN
refers to an entity but an N expresses a property of an entity. Of course, the semantic types alone do not explain
all distinctions of categories: nouns, verbs, and adjectives have the same semantic type, but different syntactic properties.
We will occasionally use the type synonyms n, a, and v instead of e -> t, to give a clearer structure to some semantic types. But from the semantic point of view, all these types are one and the same.
We should notice that the semantic types given here are quite rough and do not give a full picture of the nuances. For instance, many adjectives work in a different way than straightforwardly yielding truth values from entities. An example is
the adjective large. Being a large mouse is different (in terms of absolute size) from being a large elephant,
and a logical type for expressing this is n -> e -> t, with an argument n indicating the domain of comparison (such as
mice or elephants).
Another problem is that defining
verbs as e -> t suggests that all verbs apply to all kinds of entities. But there are combinations of entities and
verbs that make no sense semantically. For example, the verb sleep is only meaningful for animate entities, and
a sentence like this book sleeps, if not senseless, requires some kind of a metaphorical interpretation
of sleep.
The following table summarizes the most important semantic types that will be used. We use more primitive types than most traditional approaches, which reduce everything to e and t. For instance, we can't see any way to reduce the top-level category p of phrases to these types. From a type-theoretical perspective, p is the category of judgements, whereas
e and t operate on the lower level of propositions. Some more types are defined in the category tables.
| name | text name | example | definition | |
|---|---|---|---|---|
e |
entity | Paris | (primitive) | |
t |
proposition ("truth value") | Paris is large | (primitive) | |
q |
question | is Paris large | (primitive) | |
p |
top-level phrase | Paris is large. | (primitive) | |
n |
substantive ("noun") | man | e -> t |
|
a |
quality ("adjective") | large | e -> t |
|
v |
action ("verb") | sleep | e -> t |
|
np |
quantifier ("noun phase") | every man | (e -> t) -> t |
|
In addition to the features needed for inflection and agreement, the lexicon must give information about what combinations are possible with each word. For most nouns and adjective, this is simple: a noun can be modified by an adjective, for instance, and there is a uniform syntax rule for this. However, there are some nouns and adjectives that are trickier, because they don't correspond to simple things but to relations. For instance, brother is a relational noun, since its primary usage is not alone bur in phrases like brother of this man. In the same way, similar is a relational adjective, since its primary use is in phrases like similar to this. The additional term attached to these words is called its complement; thus this is the complement in similar to this. The categories of words that take complements are called subcategories. They are morphologically similar to the main categories, but need extra information for the usage of complements.
The RGL has categories for relational nouns and adjectives, and nouns also have a variant with two complements (e.g. distance from Paris to Munich). From the semantic point of you, complements are called places, and appear as supplementary argument places in semantic types. Thus the number of places is one plus the number of complements, so that the first place is reserved for the subject of a sentence and the rest of the places for the complements.
The following table shows the categories of relational nouns and adjectives in the RGL. The inflectional and inherent features are the same as for one-place nouns and adjectives, but for each complement, the lexicon must tell what preposition, if any, is needed to attach that complement. For instance, the preposition for similar is to, whereas the preposition for different is from. In languages with richer case systems (such as German, Latin, and Finnish), the complement information also determines the case (genitive, dative, ablative, and so on).
| GF name | text name | example | inherent complement features | semantics | |
|---|---|---|---|---|---|
N2 |
two-place noun | brother (of someone) | case or preposition | e -> n |
|
N3 |
three-place noun | distance (from some place to some place) | case or preposition | e -> e -> n |
|
A2 |
two-place adjective | similar (to something) | case or preposition | e -> e -> t |
|
Verbs show a particularly rich variation in subcategorization. The most familiar distinction is the one between
intransitive and transitive verbs: intransitive verbs need only a subject (like she in she sleeps),
whereas transitive verbs also need an object (like him in she loves him). Our category V obviously includes
intransitive verbs. But there is no category for transitive verbs in the RGL. Instead, we have a more general category of
two-place verbs, which includes transitive verbs but also verbs that need a preposition (such as at in
she looks at him). Just like for relational nouns and adjectives, the complement of a two-place verb has variations
in cases and prepositions.
The following table shows the subcategories of verbs in the RGL. The list is long but it may still be incomplete. For
example, there are no four-place verbs (she paid him one million pounds for the house). Such constructions can
be built, as we will see later, by using for instance a V3 verb with an additional adverb. But we can envisage
future additions of more subcategories for verbs.
| GF name | text name | example | inherent complement features | semantics | |
|---|---|---|---|---|---|
V2 |
two-place verb | love (someone) | case or preposition | e -> e -> t |
|
V3 |
three-place verb | give (something to someone) | two cases or prepositions | e -> e -> e -> t |
|
VV |
verb-complement verb | try (to do something) | infinitive form | e -> v -> t |
|
VS |
sentence-complement verb | know (that something happens) | sentence mood | e -> t -> t |
|
VQ |
question-complement verb | ask (what happens) | question mood | e -> q -> t |
|
VA |
adjective-complement verb | become (something, e.g. old) | adjective case | e -> a -> t |
|
V2V |
two-place verb-complement verb | force (someone to do something) | infinitive form, control type | e -> e -> v -> t |
|
V2S |
two-place sentence-complement verb | tell (someone that something happens) | object case, sentence mood | e -> e -> t -> t |
|
V2Q |
two-place question-complement verb | ask (someone what happens) | object case, question mood | e -> e -> q -> t |
|
V2A |
two-place adjective-complement verb | paint (something in some colour, e.g. blue) | object and adjective case | e -> e -> a -> t |
|
Of particular interest here is the infinitive form in VV and V2V. For instance, English has three such forms: bare infinitive (I must sleep), (infinitive with to (I try to sleep), and the ing form (I start sleeping).
The traditional English grammar makes a distinction between auxiliary verbs (such as must) and other verb-complement verbs (such as try and start), but this distinction is very specific to English (and some other Germanic languages) and hard to maintain in a multilingual setting like the RGL. Thus we make the distinction on the level of complement features and not on the level of categories.
The mood of complement sentences and questions is relevant in languages like French and Ancient Greek, where some verbs may require sentences in the indicative, some in another mood such as subjunctive, conjunctive, or optative. English has only a few remnants of conjunctives, such as with the verb suggest as used in I suggest that this part be struck out.
The type of control in V2V is interesting but subtle. It decides whether the verb complement of the verb agrees to the
subject or the object. An example of a subject-control verb is promise: I promised her to wash myself.
Object-control verbs seem to be more common: I forced her to wash herself, I made her wash herself, etc.
Semantically, the type e -> e -> v -> t works for both of them. However, if you consider the proposition formed by applying
them, then the two kinds of verbs apply their argument verb to different arguments:
promise subj obj verb is about the proposition verb subj
force subj obj verb is about the proposition verb obj
Hence it would make sense to distinguish between subject-control and object-control V2V's on the category level rather
than with a complement feature. The agreement behaviour would them become simpler to describe, and, what is more important,
the semantic behaviour would be predictable from the category alone.
As a final thing about subcategorizations, notice that one and the same verb can have different categories. In the above
table, ask appears in both VQ and V2Q. Now, these uses are related, in the sense that to ask something means
the same as to ask someone something. But in some other cases, the meaning can be completely different. For instance,
walk in V2 (as in I walk the dog) is different from walk in V (as in the dog walks). The V2 is in
this case causative with respect to the V: I cause the walking of the dog. From the multilingual perspective, it is
just a coincidence that English uses the same verb for the intransitive and the causative meanings. In many other languages,
different words would be used. And so would English do for many other verbs: one cannot say I eat the dog to express that I make the dog eat; the verb feed is used instead.
We have defined the categories of content along three criteria:
Thus morphological criteria are, in most languages, enough to tell apart N, A, V, and Adv.
Syntactic criteria are appealed to when distinguishing the subcategories of nouns, adjectives, and verbs.
Semantic criteria are often obeyed as well, although we have noticed that finer distinctions could be useful
for subject vs. object control verbs and for different kinds of adjectives.
For structural words, following the same criteria leads to a high number of categories, higher than in many traditional grammars. Thus, for instance the category of pronouns is divided to at least, personal pronouns (he), determiners (this), interrogative pronouns (who), and relative pronouns (that). There is no way to see all these classes as subcategories of a uniform class of pronouns, as we did with the verb subcategories: for verbs, there was a uniform set of features, to which only complement feature information had to be added, but the same does not concern the things traditionally called "pronouns".
Structural words moreover contain many categories that have no morphological variation or morphologically relevant features. For instance, interrogative adverbs (such as why) and sentential adverbs (such as always) are, in all languages we have encountered, equivalent from the morphological point of view. Yet of course they are syntactically different, as one cannot convert why are you always late into always are you why late. And semantically, sentential adverbs modify actions whereas interrogative adverbs form questions from sentences.
The following tables give a summary of the structural word categories of the RGL, equipped with morphological and semantic information as we did for content words. The full details will be best explained in the sections on syntax, i.e. on how the structural words are actually used for building structures.
Building noun phrases
| GF name | text name | example | inflectional features | inherent features | semantics | |
|---|---|---|---|---|---|---|
Det |
determiner | every | gender, case | number, definiteness | det = n -> (e -> t) -> t |
|
Quant |
quantifier | this | gender, number, case | definiteness | num -> det |
|
Predet |
predeterminer | only | gender, number, case | (none) | np -> np |
|
Pron |
personal pronoun | he | case, possessives | gender, number, person | e |
|
The most important thing to notice is the distinction between Det and Quant. The latter covers determiners that have
"two forms", for both numbers, such as this-these and that-those. The former covers determiners with a fixed number,
such as every (singular).
Building number expressions
| GF name | text name | example | inflectional features | inherent features | semantics | |
|---|---|---|---|---|---|---|
Num |
number expression | five | gender, case | number | num = det |
|
Card |
cardinal number | five | gender, case | number | num = det |
|
Ord |
ordinal number | fifth | gender, number, case | (none) | e -> t |
|
Numeral |
verbal numeral | five | gender, case, card/ord | number | num |
|
Digits |
numeral in digits | 511 | card/ord | number | num |
|
AdN |
numeral-modifying adverb | almost | (none) | (none) | num -> num |
|
Notice: under Numeral, there is a category structure of its own, which is however of a technical
nature and needs usually no attention by the library users.
Building interrogatives and relatives
| GF name | text name | example | inflectional features | inherent features | semantics | |
|---|---|---|---|---|---|---|
IP |
interrogative pronoun | who | case | gender, number | (e -> t) -> q |
|
IDet |
interrogative determiner | how many | gender, case | number | n -> (e -> t) -> q |
|
IQuant |
interrogative quantifier | which | gender, number, case | (none) | num -> n -> (e -> t) -> q |
|
IAdv |
interrogative adverb | why | (none) | (none) | t -> q |
|
RP |
relative pronoun | that | gender, number, case | gender, number | (e -> t) -> rel |
|
The interrogative pronoun structure replicates a part of the determiner structure. For instance, IQuant such as
which is usable for both singular and plural, whereas IDet has a fixed number: how many is plural.
Combining sentences
| GF name | text name | example | inflectional features | inherent features | semantics | |
|---|---|---|---|---|---|---|
Conj |
conjunction | and | (none) | number; continuity | t -> t -> t |
|
PConj |
phrasal conjunction | therefore | (none) | (none) | p -> p |
|
Subj |
subjunction | if | (none) | mood | t -> adv |
|
Adverbial expressions
| GF name | text name | example | inflectional features | inherent features | semantics | |
|---|---|---|---|---|---|---|
AdV |
sentential adverb | always | (none) | (none) | v -> v |
|
CAdv |
comparative adverb | as | (none) | (none) | a -> e -> a |
|
Prep |
preposition | through | (none) | case, position | np -> adv |
|
One more thing to be taken into account is that many of the "structural word categories" also admit of complex
expressions and not only words. That is, the RGL has not only words in these categories but also syntactic
rules for building more expressions. Thus for instance these five is a Det built from the Quant this
and the Num five. It is also common that a "structural word" in a particular language is realized as
a feature of the other words it combines with, rather than as a word of its own. For instance,
the determiner the in Swedish just selects an inflectional form of the noun that it is applied to:
"the" + bil = bilen ("the car").
The first task when defining the language-specific rules for linguistic structures in the RGL is to give the actual ranges of the features attached to the categories. We have to tell whether the language has the grammatical number (as e.g. Chinese has not), and which values it takes (as many languages have two numbers but e.g. Arabic has three). We have to do likewise for case, gender, person, tense - in other words, to specify the parameter types of the language. Then we have to proceed to specifying which features belong to which lexical categories and how (i.e. as inflectional or inherent features). In this process, we may also note that we need some special features that are complex combinations of the "standard" features (as happens with English verbs: their forms are depend on tense, number, and person, but not as a straightforward combination of them). We may also notice that a "words" in some category may in fact consist of several words, which may even appear separated from each other. English verbs such as switch off, called particle verbs, are a case in point. The particle contributes essentially to the meaning of the verb, but it may be separated from it by an object: Please switch it off!
| GF name | text name | values | |
|---|---|---|---|
Number |
number | singular, plural | |
Person |
person | first, second, third | |
Case |
case | nominative, genitive | |
Degree |
degree | positive, comparative, superlative | |
AForm |
adjective form | degrees, adverbial | |
VForm |
verb form | infinitive, present, past, past participle, present participle | |
VVType |
infinitive form (for a VV) | bare infinitive, to infinitive, ing form | |
The assignment of parameter types and the identification of the separate parts of categories defines the data structures in which the words are stored in a lexicon. This data structure is in GF called the linearization type of the category. From the computer's point of view, it is important that the data structures are well defined for all words, even if this may sound unnecessary for the human. For instance, since some verbs need a particle part, all verbs must uniformly have a storage for this particle, even if it is empty most of the time. This property is guaranteed by an operation called type checking. It is performed by GF as a part of grammar compilation, which is the process in which the human-readable description of the grammar is converted to bits executable by the computer.
| GF name | text name | example | inflectional features | inherent features | |
|---|---|---|---|---|---|
N |
noun | house | number, case | (none) | |
PN |
proper name | Paris | case | (none) | |
A |
adjective | blue | adjective form | (none) | |
V |
verb | sleep | verb form | particle | |
Adv |
adverb | here | (none) | (none) | |
V2 |
two-place verb | love | verb form | particle, preposition | |
VV |
verb-complement verb | try | verb form | particle, infinitive form | |
VS |
sentence-complement verb | know | verb form | particle | |
VQ |
question-complement verb | ask | verb form | particle | |
VA |
adjective-complement verb | become | verb form | particle | |
Notice that we have placed the particle of verbs in the inherent feature column. It is not a parameter but a string. We have done the same with the preposition strings that define the complement features of verb and other subcategories.
The "digital grammar" representations of these types are records, where for instance the VV
record type is formally written
{s : VForm => Str ; p : Str ; i : InfForm}
The record has fields for different types of data. In the record above, there are three fields:
s, storing an inflection table that produces a string (Str) depending on verb form,
p, storing a string representing the particle,
i, storing an inherent feature for the infinitive form required
Thus for instance the record for verb-complement verb try (to do something) in the lexicon looks as follows:
{s = table {
VInf => "try" ;
VPres => "tries" ;
VPast => "tried" ;
VPastPart => "tried" ;
VPresPart => "trying"
} ;
p = "" ;
i = VVInf
}
We have not introduce the GF names of the features, as we will not make essential use of them: we will prefer informal explanations for all rules. So these records are a little hint for those who want to understand the whole chain, from the rules as we state them in natural language, down to machine-readable digital grammars, which ultimately have the same structure as our statements.
In many languages, the description of inflectional forms occupies a large part of grammar books. Words, in particular verbs, can have dozens of forms, and there can be dozens of different ways of building those forms. Each type of inflection is described in a paradigm, which is a table including all forms of an example verb. For other verbs, it is enough to indicate the number of the paradigm, to say that this verb is inflected "in the same way" as the model verb.
Computationally, inflection paradigms are functions that take as their arguments stems, to which suffixes (and sometime prefixes) are added. Here is, for instance, the English regular noun paradigm:
| form | singular | plural | |
|---|---|---|---|
| nominative | dog | dogs | |
| genitive | dog's | dogs' | |
As a function, it is interpreted as follows: the word dog is the stem to which endings are added. Replacing it with cat, donkey, rabbit, etc, will yield the forms of these words.
In addition to nouns that are inflected with exactly the same suffixes as dog, English has inflection types such as fly-flies, kiss-kisses, bush-bushes, echo-echoes. Each of these inflection types could be described by a paradigm of its own. However, it is more attractive to see these as variations of the regular paradigm, which are predictable by studying the singular nominative. This leads to a generalization of paradigms which in the RGL are called smart paradigms.
Here is the smart paradigm of English nouns. It tells how the plural nominative is formed from the singular; the genitive forms are always formed by just adding 's in the singular and ' in the plural.
The same rules are in GF expressed by regular expression pattern matching which, although formal and machine-readable, might in fact be a nice notation for humans to read as well:
"s" | "z" | "x" | "sh" | "ch" => <word, word + "es">
#vowel + "y" => <word, word + "s">
"y" => <word, init word + "ies">
(#vowel | "y") + "o" => <word, word + "s">
"o" => <word, word + "es">
_ => <word, word + "s">
In this notation, | means "or" and + means "followed by". The pattern that is matched is followed by
an arrow =>, after which the two forms appear within angel brackets. The patterns are matched in the given
order, and _ means "anything that was not matched before". Finally, the function init returns the
initial segment of a word (e.g. happ for happy), and the pattern #vowel is defined as
``"a" | "e" | "i" | "o" | "u".
In addition to regular and predictable nouns, English has irregular nouns, such as man - men, formula - formulae, ox - oxen. These nouns have their plural genitive formed by 's: men's.
English adjectives inflect for degree, with three values, and also have an adverbial form in their linearization type. Here are some regular variations:
The comparison forms only work for adjectives with at most two syllables. For longer ones, they are formed syntactically: expensive, more expensive, most expensive. There are also some irregular adjectives, the most extreme one being perhaps good, better, best, well.
English verbs have five different forms, except for the verb be, which has some more forms, e.g. sing, sings, sang, sung, singing. But be is also special syntactically and semantically, and is in the RGL introduced in the syntax rather than in the lexicon.
Two forms, the past (indicative) and the past participle are the same for the so-called regular verbs (e.g. play, plays, played, played, playing). The regular verb paradigm thus looks as follows:
| feature | form | |
|---|---|---|
| infinitive | play | |
| present | plays | |
| past | played | |
| past participle | played | |
| present participle | plays | |
The predictable variables are related to the ones we have seen in nouns and adjectives: the present tense of verbs varies in the same way as the plural of nouns, and the past varies in the same way as the comparative of adjectives. The most important variations are
English also has a couple of hundred irregular verbs, whose infinitive, past, and past participle forms have to stored separately. These free forms determine the other forms in the same way as regular verbs. Thus
The rules of syntax specify how words are combined to phrases, and how phrases are combined to even longer phrases. Phrases, just like words, belong to different categories, which are equipped with inflectional and inherent features and with semantic types. Moreover, each syntactic rule has a corresponding semantic rule, which specifies how the meaning of the new phrases is constructed from the meanings of its parts.
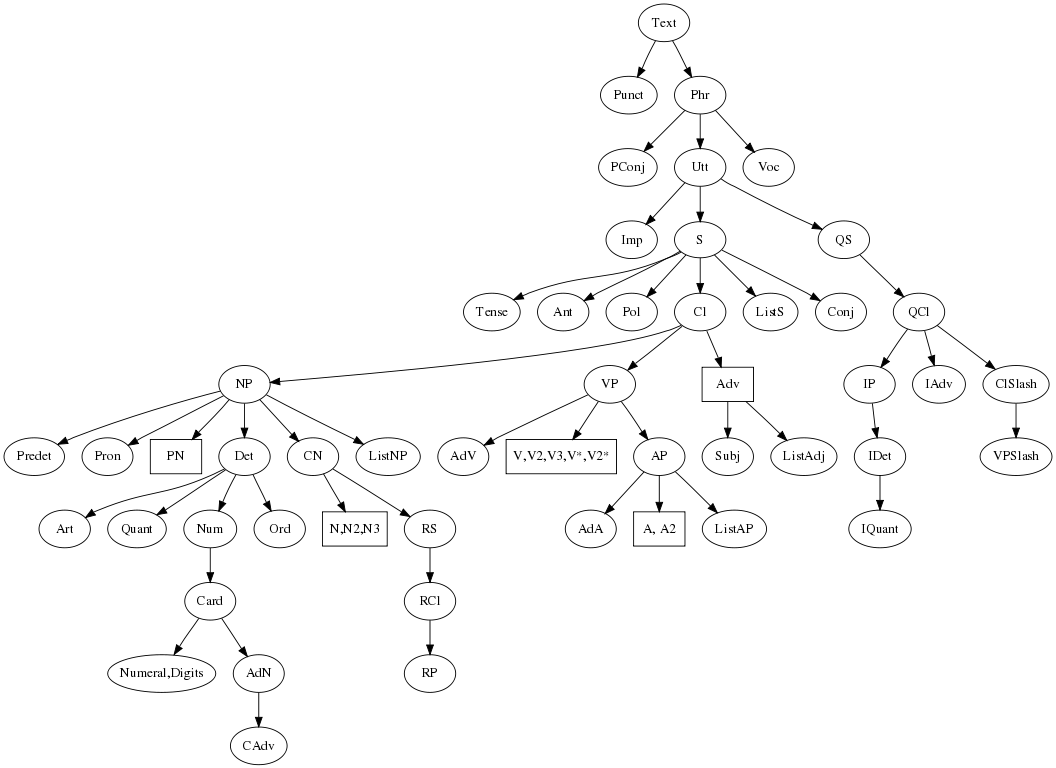
The RGL has around 30 categories of phrases, on top of the lexical categories. The widest category is Text, which cover
entire texts consisting of sentences, questions, interjections, etc, with punctuation. The following picture shows all RGL
categories as a dependency tree, where Text is in the root (so it is an upside-down tree), and the lexical categories
in the leaves. Being above another category in the tree means that phrases of higher categories can have phrases of lower
categories as parts. But these dependencies can work in both directions: for instance, the noun phrase (NP)
every man who owns a donkey has as its part the relative clause (RCl), which in turn has its part the noun phrase
a donkey.
Lexical categories appear in boxes rather than ellipses, with several categories gathered in some of the boxes.
It is convenient to start from the middle of the RGL: from the structure of a clause (Cl). A clause is an application
of a verb to its arguments. For instance, John paints the house yellow is an application of the V2V verb paint
to the arguments John, the house, and yellow. Recalling the table of lexical categories from Chapter 1,
we can summarize the semantic types of these parts as follows:
paint : e -> e -> (e -> t) -> t
John : e
the house : e
yellow : e -> t
Hence the verb paint is a predicate, a function that can be applied to arguments to return a proposition. In this case, we can build the application
paint John (the house) yellow : t
which is thus an object of type t.
Applying verbs to arguments is how clauses work on the semantic level. However, the syntactic fine-structure is a bit more complex. The predication process is hence divided to several steps, which involve intermediate categories. Following these steps, a clause is built by adding one argument at a time. Doing in this way, rather than adding all arguments at once, has two advantages:
Here are the steps in which John paints the house yellow is constructed from its arguments in the RGL:
VPSlash)
VP)
Cl)
The structure is shown by the following tree:
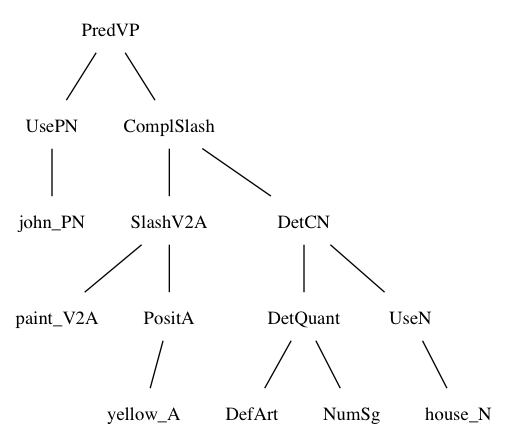
PredVP encodes the rule that combines a noun phrase and a verb phrase into a clause,
UsePN converts a proper name to a noun phrase, and so on. Mathematically, these names
denote functions that build abstract syntax trees from other tree. Every tree belongs to some category.
The GF notation for the PredVP rule is
PredVP : NP -> VP -> Cl
in words, PredVP is a function that takes a noun phrase and a verb phrase and returns a clause.
The tree is thus in fact built by function applications. A computer-friendly notation for trees uses parentheses rather than graphical trees:
PredVP
(UsePN john_PN)
(ComplSlash
(SlashV2A paint_V2A (PositA yellow_A))
(DetCN (DetQuant DefArt NumSg) (UseN house_N)))
Before going to the details of phrasal categories and rules, let us compare the abstract syntax tree with another tree, known as parse tree or concrete syntax tree:

VPSlash, this part can consist of many separate groups of words, where words from constructions from
higher up are inserted.
As parse trees display the actual words of a particular language, in a language-specific order, they are less interesting from the multilingual point of view than the abstract syntax trees. A GF grammar is thus primarily specified by its abstract syntax functions, which are language-neutral, and secondarily by the linearization rules that convert them to different languages.
Let us specify the phrasal categories that are used for making up predications. The lexical category V2A of
two-place adjective-complement verbs was explained in Chapter 1.
| GF name | text name | example | inflection features | inherent features | parts | semantics | |
|---|---|---|---|---|---|---|---|
Cl |
clause | he paints it blue | temporal, polarity | (none) | one | t |
|
VP |
verb phrase | paints it blue | temporal, polarity, agreement | subject case | verb, complements | e -> t |
|
VPSlash |
slash verb phrase | paints - blue | temporal, polarity, agreement | subject and complement case | verb, complements | e -> e -> t |
|
NP |
noun phrase | the house | case | agreement | one | (e -> t) -> t |
|
AP |
adjectival phrase | very blue | gender, numeber, case | position | one | a = e -> t |
|
TODO explain agreement and temporal.
TODO explain the semantic type of NP.
The functions that build up the clause in our example tree are given in the following table, together with functions that build the semantics of the constructed trees. The latter functions operate on variables belonging to the semantic types of the arguments of the function.
| GF name | type | example | semantics | |
|---|---|---|---|---|
PredVP |
NP -> VP -> S |
he + paints the house blue | np vp |
|
ComplSlash |
VPSlash -> NP -> VP |
paints - blue + the house | \x -> np (\y -> vpslash x y) |
|
SlashV2A |
V2A -> AP -> VPSlash |
paints + blue | \x,y -> v2a x y ap |
|
TODO explain lambda abstraction.
The semantics of the clause John paints the house yellow can now be computed from the assumed meanings
John* : e
paint* : e -> e -> (e -> t) -> t
the_house* : e
yellow* : e -> t
as follows:
(PredVP John (ComplSlash (SlashV2A paint yellow) the-house))*
= (ComplSlash (SlashV2A paint yellow) the_house)* John*
= (SlashV2A paint yellow)* John* the_house*
= paint* John* the_house* yellow*
for the moment ignoring the internal structure of noun phrases, which will be explained later.
The linearization rules work very much in the same way as the semantic rules. They obey the definitions of inflectional and inherent features and discontinuous parts, which together define linearization types of the phrasal categories. These types are at this point schematic, because we don't assume any particular language. But what we can read out from the category table above is as follows:
| GF name | text name | linearization type | |
|---|---|---|---|
Cl |
clause | {s : Temp => Pol => Str} |
|
VP |
verb phrase | {v : V ; c : Agr => Str ; sc : Case} |
|
VPSlash |
slash verb phrase | {v : V ; c : Agr => Str ; ; sc, cc : Case} |
|
NP |
noun phrase | {s : Case => Str ; a : Agr} |
|
AP |
adjectival phrase | {s : Gender => Number => Case => Str ; isPre : Bool} |
|
TODO explain these types, in particular the use of V
These types suggest the following linearization rules:
PredVP np vp = {s = \\t,p => np.s ! vp.sc ++ vp.v ! t ! p ! np.a ++ vp.c ! np.a}
ComplSlash vpslash np = {v = vpslash.v ; c = \\a => np.s ! vpslash.cc ++ vpslash.c ! a}
SlashV2A v2a ap = {v = v2a ; c = ap.s ! v2a.ac ; cc = v2a.ap}
TODO explain these rules
The linearization of the example goes in a way analogous to the computation of semantics. It is in both cases compositional, which means that the semantics/linearization only depends on the semantics/linearization of the immediate arguments, not on the tree structure of those arguments. Assuming the following linearizations of the words,
John* : mkPN "John"
paint* : mkV "paint" ** {cc = Acc ; ca = Nom}
the_house* : mkPN "the house"
yellow* : mkA "yellow"
we get the linearization of the clause as follows:
(PredVP John (ComplSlash (SlashV2A paint yellow) the-house))*
= "John" ++ vp.v ! SgP3 ++ vp.c ! SgP3
where vp = (ComplSlash (SlashV2A paint yellow) the_house)*
= {v = mkV "paint" ; c = \\_ => "the house yellow"}
= "John paints the house yellow"
Similar rules as to V2A apply to all subcategories of verbs. The V2 verbs are first made into VPSlash
by giving the non-NP complement. V3 verbs can take their two NP complements in either order, which
means that there are two VPSlash-producing rules. This
makes it possible to form both the questions what did she give him and whom did she give it.
The other V categories are turned into VP without going through VPSlash, since they have
no noun phrase complements.